
Git is a tool, lets try to use it like one.
![]()
Git is an exceptional tool when it comes to source control management, but it still requires a level of knowledge to use properly. No one would let an untrained person use heavy machinery, and git is no different. While a mistake may not cost you thousands of dollars in physical damage in using git, it may result in millions in damages if sensitive information is leaked online. Countless users incorrectly use git and this causes news headlines throughout the world. Proper training seems to be scarce in this space, and I felt a brief overview on my experiences in git may prove useful to some.
Proper tool use
While git, like every tool, has a very loose user guide, there are still many best practices that should be followed to prevent harm. This includes understanding the quick way is not always the correct way. While not every best practice under the sun must be followed, it is a great Idea to read up on all the ways people are using and streamlining security into their use of git.
Not-Good Practice
It may be alluring to run a quick command to add your files and commit them all at once, but what if this adds files you don’t want public?
#!/usr/bin/env bash
git add *
git commit -m '<USER NAME> Auto push change'
git push -f origin master
The above is an actual code example that a fellow developer had aliased out to his local shell and used to streamline his coding commits.
There are many things wrong with this specific approach above. Before I dive into what could go wrong, I must say that I am not against setting up user aliases that can streamline process. For example, typing in git commit -m every time gets tiresome, and I have this aliased myself. However, putting an alias that makes drastic assumptions on the intended flow is neither safe nor appropriate; especially with git.
Diving back into the example, the first thing wrong it assuming we are adding EVERY file into source. git add * essentially takes the current working directory, and adds all files that are not included in a .gitignore to the commit.
Now let’s say you have a test configuration file with sensitive information for a development database stored locally in the working directory. While this is still a bad practice, it typically will not cause any issues, as it will be short lived, and probably removed soon after testing. However, running the above alias would add this config file into the commit and push it right up to source. Now this “short lived” file is available in the commit history of the repository until the end of time (or until the repo is deleted).
By using this shortcut alias, you have inadvertently added sensitive information to your commit, and potentially exposed your database to harm. And the worst part about this situation is that it may be hours or even days until it is discovered by you or another member of your team/community, and that is the best case scenario.
The more likely outcome is a black hat is now in possession of the details to the development system through automated crawling of repositories.
Lets break down what not to do in this scenario.
git add
Bad approach
git add *
This is a clear no-go approach. You should never openly add everything in the working directory to git. As many precious seconds as it takes, the better approach would be to selectively add the files that have been changed.
Good approach
git add README.md src/files/i/changed.conf
This will only add to the commit the files explicitly stated in the add command. Now you don’t need to rely on a complete .gitignore to protect you (nor should you ever).
git commit
git commit -m '<USER NAME> Auto push change'
This is a bad thing to do because a commit message should have details on what was changed and how it impacts the code. Meaningful commit messages are how useful change-logs and release notes are generated, so for the longevity of the repository, it is worth it to take a few extra seconds and write out a proper message. More information can be read on branching strategies and how they can affect the history also.
git push
git push -f origin master
There are a few things wrong here. First and foremost, using the -f flag, or --force should only be done in the most extreme of situations. Arbitrary use of the force flag should not be done as a regular occurrence.

Any reason a commit would be rejected from the remote is usually the appropriate behavior. It means the commit history on your local branch is either behind or inconsistent with the history on the remote. By ignoring this and forcing the commit, you essentially rewrite what is the “source of truth” to the commit chain you have local, potentially overwriting changes that have been committed by other developers. If you know for a fact that you were the last developer to commit and you are trying to fix an issue you caused in a critical branch, forcing may be appropriate, but usually it is not.
A better approach would be to simply remove the -f flag to allow git to manage its history, and reject commits when they should.
Why use force
The few reasons that force should be used must also be documented.
One reason to use force is to clean up old history of commits that may contain sensitive information. If code is already on the remote server, and you need to remove the sensitive commits from days or even weeks ago, the only way to do so is to clean the history locally with a rebase, which will ultimately require a final git push --force.
Another reason could be if there is an emergency situation where code that was broken was pushed to a release stage, git push --force may be appropriate.
However, This can only be done safely if you are the last one to commit to this release branch, and you can verify no other users will commit/pull during this time. If these both are true, a forced commit to fix a breaking change could be done. Even if a small commit gets through in this time, it is best to NOT force push, and instead consider it a hot-fix that follows the standard merge procedures.
The --force flag is also very much opinion based, so there may be a specific workflow that operates around the force concept (maybe maintaining a commits’ SHA into master?), but I personally cannot fathom a reason outside of an emergency.
In general this entire alias should be avoided. Every logical step in the git process should be critiqued to avoid sensitive leaks and clean git histories.
Branches Strategy
Another topic most people struggle with is the concept of branches. A Branch is a way to diverge a codeline to a workable target. A common term is a “feature-branch” which is a copy of the main branch where all development work is done, and then merged back in to the main branch through a pull request.
Orchestrating a proper strategy to this is key to project longevity.
Using git, I consider there to be three main approaches to branching.
- gitflow
- trunking
- three-flow
All of these strategies work, it is just up to the team to implement it properly.
By themselves, the branching strategy does not solve any underlying issue teams may have, so don’t arbitrarily enforce any one of these as a solution.
Gitflow
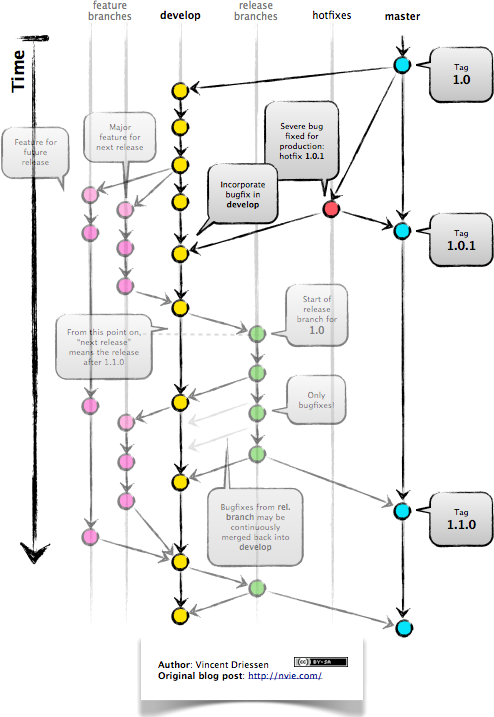
Without the semantics of what gitflow is, this is the most common approach teams take when starting to use git.
There are many different branches that are in flight at any time, but the main concept is that master is the defacto release branch.
The issue we can get into very quickly is when branches become long lived, and end up with many conflicting commits, or when hotfixes are not applied appropriately to master. To this end, the master branch then becomes the parking lot for all code, but not necessarily the release.
Trunking
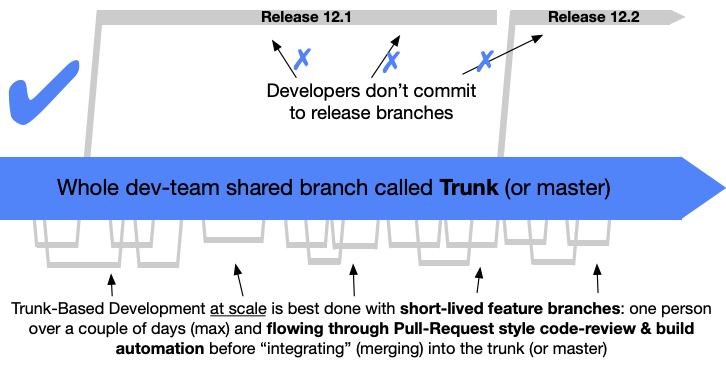
This approach was popularized by Google, and for good reason. It takes the concept of master as the source of truth, and the assumed “trunk” of the git tree. All commits are made directly to the trunk branch, and releases are “cut” from the trunk.
Once these releases are cut, they are never committed to directly. This way, code is always releasable from master, and feature branches are very short lived.
It does require a high level of discipline to avoid issues when committing directly to master, and usually has large scale CI/CD tooling for automated reviews and testing for any changes that may be introduced. This is usually something smaller teams or inexperienced teams really struggle with.
Three-Flow
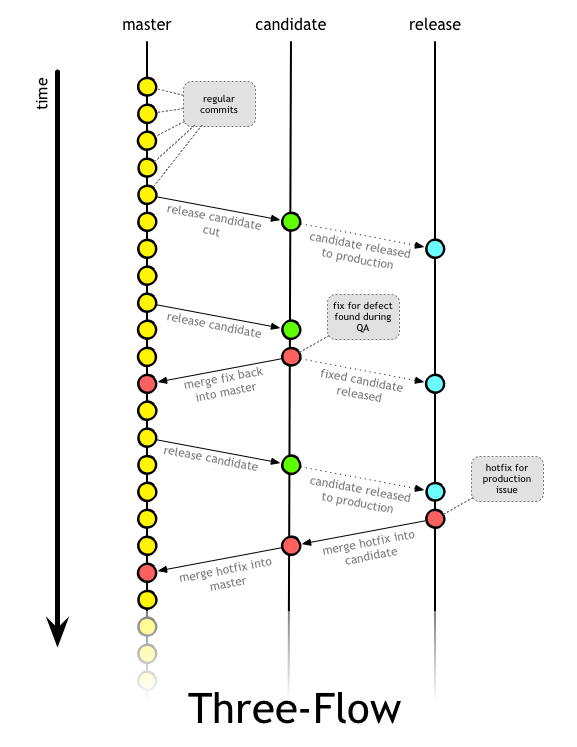
A newer concept in the same chain as git flow is the three-flow concept. This takes the git flow concept and moves it into only using 3 branches, all of which are long long lived. master is still the primary focus for all work, but there are two additional branches; candidate and release.
These two branches are essentially the RC and Release itself, and it works through a tagging cut process similar to trunking. This means master is always the most up to date branch, but releases are not cut directly from it. Instead the release is tested in the candidate branch (merged from master) and then the intended release is cut to the release branch as a single commit.
Again, it takes a higher degree of discipline in this strategy to sync the commits across the branches where needed. A single hotfix not maintained across all three branches will essentially break this flow completely.
Other Good Practices
There are many other things a user should be aware of when using git. So far, I have only scratched the surface of git and how most developers use it.
- Merge Strategies
- Rebase, fast forwards and squashes are all terms I hear thrown around and people always seem to have an opinion on one of them. However, very few actually understand the full implications of each.
- Atlassian has a great write-up on how each merge strategies work, and is definitely worth a read.
- Signing commits
- Most source control systems allow the users to add GPG keys to verify a commit. This adds a flag signalling a commit made by the user is verified by the GPG key that was signed to it, proving it was the correct person. I won’t go into the details on what GPG keys are or how to use them, but github has a great article on how to use them. In practice, you can even prevent commits from being merged in if they were not signed, which could be a boon to security if executed properly.
- Tagging
- You should follow the standard semantic versioning for any release you make via MAJOR.MINOR.PATCH. It is also best practice to append a
vto the beginning of every version (at least from github’s standard) but it is not required. In the 2.0.0 semver standard, it is considered optional.
- You should follow the standard semantic versioning for any release you make via MAJOR.MINOR.PATCH. It is also best practice to append a
Specifics every Repo Should Have
This is a list of the things [I feel] every repository should have. There are a few that are specific to the platform they are located on, but nearly all should be included in every repository created.
Base
These files should ALWAYS exist in your repo unless a reason indicated is not applicable.
.gitignore- This file should always be included no matter what. This essentially prevents unwanted files from ending up in the commit history. These could include build directories from local testing as well as any cache or hidden files that could be added in error. The most common use is to avoid adding the .git folder as well as language specific patterns. While it could also prevent sensitive information from being added, it should never be considered standard practice to use it in such a way, as doing so could still expose system patterns or naming conventions that a developer is using.
- A great resource straight from github: Gitignore Examples
.editorconfig- This file is not always needed, but is extremely valuable when working with multiple developers. Everyone has their own style syntax and IDE, and keeping them in line is a challenge. Committing an .editorconfig file will keep this much more synchronized.
- See the main page for info: EditorConfig
README.md- The ‘What is this thing’ of your repository. This file serves as an explanation on what your repository is for, and a general guide on how to use it. This also should never have an exception unless the goal is to make difficult to use and understand code.
*/**/README.md(wherever most applicable to describe use)- Including more than one README may also be appropriate if there are many directories that house very specific code that may not be appropriate to separate into a different repository.
CONTRIBUTING.md- This file is also a huge value add for opensource projects. It essentially provides a guideline on how any other developer could add to your project. Many projects include this file, but don’t flesh it out, and instead point to a WIKI that has more details. Either way, it can be a great help in providing outsiders a way to assist.
- The Atom.io CONTRIBUTING.md file is a great example of a fully fleshed out Contribution guide.
LICENSE.txt- An included License file is also a huge requirement to prevent legal troubles in the future. If you want your code to be truly free and open source, you must License your code to be so.
- LINK: Licensing a Repository
CHANGELOG.md- While not always required, it is a great tool to track major changes to a project that directly affect end users. This could be a combination of multiple fixes or version changes from related issues all packed into one. Proper linking to issues is very helpful for tracing back older changes, rather than forcing users to spelunk down the commit chain.
CODEOWNERS(github)- A relative new file that is invaluable when using github. This file can be used to enforce reviews required for specific users during pull request. This is especially useful for teams that have many different locations for code within the same repo, and each could require specific SMEs to review. Rather than loosely requiring the review, this file strictly enforces the users that must give their blessing.
CI/Build FileJenkinsfile/.travis.yml/.circleci/*/.gitlab-ci.ymletc.- These files are the main “Continuous Integration” components when dealing with any repository. It provides the distributed ability for any maintainer to receive feedback in a near instant manner for any commit they make. These files are specific for the build and project you are working on, but in most organizations there will be a requirement of one of these.
Docker specific
While not directly requirements for git, these files are invaluable in a Container focused world.
.dockerignore- A usually overlooked file when dealing with Docker, this can drastically reduce your container size when doing general
ADDorCOPYcommands in your Dockerfile. This could also save you some headache when omitting certain directories from the container that have no right being included (such as .git/). While it could be argued that an explicit Dockerfile could have no need for .dockerignore, it is a great tool to preventing the occasional “oops” moments.
- A usually overlooked file when dealing with Docker, this can drastically reduce your container size when doing general
Dockerfile- A docker project is never complete without a Dockerfile. This is the proverbial “meat and potatoes” delivery system for any Containerized project. There is almost never a reason to not include a raw Dockerfile in your code if the end product is a Containerized output. In a similar way to how pip is used for python packages, you should use the tool that was designed for this approach.
docker-compose.yml- if needed- A lesser used file, but a great tool for multi-container orchestration, docker-compose provides a way to deploy a multi container “app” with a single configuration file. This could prove useful for a build test or even a production end-state. Docker compose can provide the end users a very easy quick-start to your container application.
- LINK: Docker-Compose
Reference
Git Strategies - Atlassian take on strategies (great visuals)
Signing commits - Github’s take on GPG keys
Semantic Versioning - Semver standard
Gitignore - Github examples for language specific .gitignores
CONTRIBUTING.md example from Atom.io
Licensing a Repository - Licensing support for OpenSource